The Agent Control Plane: Run Agents With Control
Enterprise AI Strategy
AI Risk & Safety
Nov 25, 2025

Agent demos impress. Production reality audits. Leaders now want proof that agents can act inside clear permissions, leave a complete trail, and roll back in seconds when something goes wrong. An agent control plane delivers that proof. It defines what an agent may do, how it does it, who approves risky actions, how spend is monitored, and how every step is captured for review. Get this right and you keep velocity without inviting chaos.
What the control plane is
The control plane is a thin governance layer that sits between your models and your business workflows. It lists the tools an agent can use. It sets scopes and approval rules. It tracks cost and latency. It records prompts, retrieval sources, tool calls, and outputs as signed events. Think of it as a fenced factory. Tools are cataloged. Paths are marked. Meters are visible. Evidence is automatic.
Why this matters now
Enterprises see strong agent prototypes yet struggle to cross the gap from demo to durable value. The blockers are consistent.
• Tools and scopes are undefined.
• Human review exists but slows delivery.
• Spend is opaque and unit economics are missing.
• Evidence is spread across tickets, chats, and notebooks.
The control plane turns those gaps into operating controls.
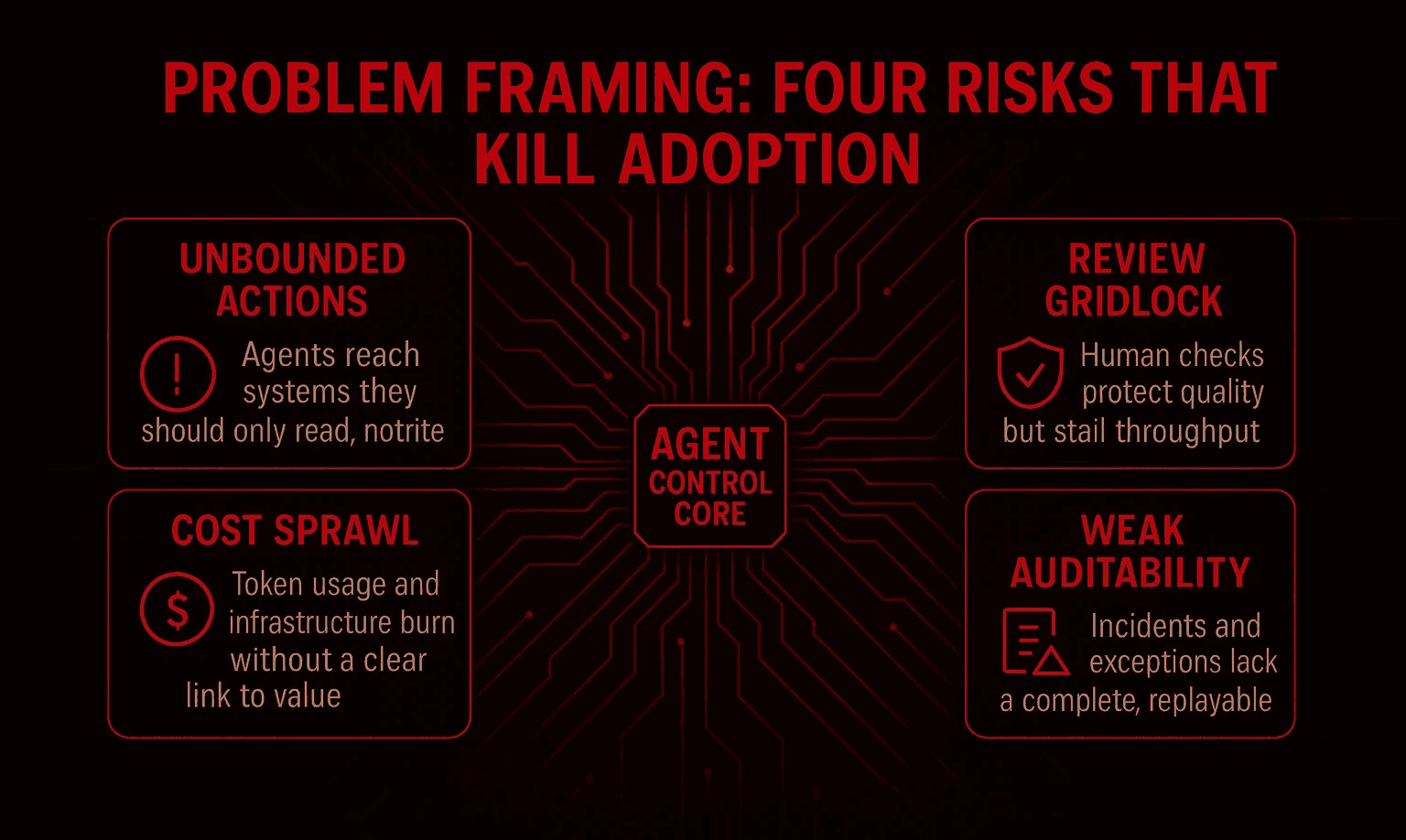
Problem framing: four risks that kill adoption
Unbounded actions: Agents reach systems they should only read, not write.
Review gridlock: Human checks protect quality but stall throughput.
Cost sprawl: Token usage and infrastructure burn without a clear link to value.
Weak auditability: Incidents and exceptions lack a complete, replayable record.
Your goal is not only to prevent failure. Your goal is to preserve speed while building trust. That requires clarity at the tool edge, quick human decisions, live cost telemetry, and an evidence trail that stands up in a review.
Inventory of tools and scopes
Start with a registry. Treat each tool as a contract.
For every tool record:
• Name and owner.
• Inputs and outputs.
• Side effects and risk class.
• Default scope and hard limits.
• Approval path for out-of-bounds actions.
• Version history and signatures.
Scope before policy: Restrict at the gateway rather than inside prompts. For example, the procurement agent may read vendor data and draft a purchase order up to a fixed amount. Above that threshold an approver must confirm. In finance, an agent may create a ledger entry but may not post without a second check. Scopes reduce ambiguity. They also make testing simpler and help auditors understand control intent. Classify tool risk and approvals with Gartner AI TRiSM concepts to keep policies consistent as adoption grows.
Minimum bar for enforcement:
• All tool calls pass through a gateway that enforces scope.
• Every call carries a stable route ID and a signed request.
• Every response is signed and time stamped.
Human in the loop that keeps flow
Human review should protect the edges rather than stop the line. Use triage and service levels.
Three lanes work best.
• Green lane: High confidence and low risk. Auto-approve.
• Amber lane: Medium confidence or medium risk. Fast review queue with a clear service level such as five minutes during business hours.
• Red lane: Low confidence or high risk. Full review with a named owner.
Reviewers must see the prompt, the retrieved context, the plan, the tool calls with parameters, and the proposed action. They approve, modify, or block and give a short reason. The decision and rationale go to the log.
Metrics to tune every week:
• Median approval time in the amber lane.
• Override rate and the top three reasons.
• False blocks and missed blocks by route.
If approval times rise or false blocks spike, you adjust thresholds and training. The goal is stable flow with clear guardrails.
Budgets and spend telemetry
Boards will ask about cost before they ask about accuracy. Treat spend as a first-class signal.
Controls to implement:
• Token ceilings per route and per agent.
• Time budgets for expensive chains and tools.
• Routing rules that send easy tasks to small local models and reserve large models for hard cases.
• Batch windows and caching where the user experience allows it.
Metrics to publish:
• Cost per task for the top five routes.
• P95 latency per route.
• Cache hit rate and the measured quality delta.
• Spend by quarter against value created such as hours saved, revenue protected, or recovery time reduced.
Once finance can read cost per task and compare it with value per task, agents graduate from experiments to line items with a return.
Evidence by default
If you cannot export proof in a minute, you do not have control. Emit structured events and give each event a stable ID and a signature.
Minimum event set:
• Prompt and response with hash IDs.
• Retrieval sources with document IDs and versions.
• Tool calls with parameters, scopes, and results.
• Guardrail hits and blocked actions.
• Human approvals, overrides, and reasons.
• Rollback events with before and after state.
Send events to your SIEM with retention windows that match your regulatory posture. Build a reviewer view that links one business decision to its prompts, context, tools, approvals, and outputs. A manager can read it in a minute. An auditor can verify the artifacts. Map your logging and review model to the NIST AI Risk Management Framework so risk teams can reuse familiar roles and controls.
Governance that makes decisions
Hold a monthly or quarterly agent review. Keep it short and decisive.
One page per workflow includes:
• Current controls and any changes since the last review.
• Incidents and near misses with links to evidence packets.
• Spend, latency, and value delivered.
• Open exceptions and due dates.

Label each route scale, fix, or sunset. Record owners and actions. Tie actions to change management so the adjustments are tracked and approved. The review exists to make decisions and to close the loop on risk, not to admire dashboards.
KPIs a board can read at a glance
• Share of critical workflows under the control plane.
• Blocked actions per week and confirmed false blocks.
• Mean time to rollback for risky routes.
• Cost per task and value per task for the top workflows.
• Incidents with complete evidence packets.
• Mean time to assemble an exportable packet.
• P95 latency by route and trend over time.
Twelve-week path to production
Weeks 1 to 2: Pick one workflow that moves money or sensitive data. List tools, scopes, risks, and approval paths.
Weeks 3 to 4: Stand up the registry and the gateway. Enforce scope on every tool call. Add signatures to requests and responses.
Weeks 5 to 6: Build the triage queues and the review UI. Set service levels for the amber lane.
Weeks 7 to 8: Add routing and cost telemetry. Introduce caching where safe and measure quality deltas.
Weeks 9 to 10: Emit the full event set to your SIEM. Build the reviewer view and the one-minute export.
Weeks 11 to 12: Run a red team exercise. Hold the first governance review. Label the route scale, fix, or sunset and publish the KPIs.
Case vignette
A defense client faced rising compliance effort and slow releases. We inserted an agent control layer across change management and evidence workflows.
• Sixty percent of manual checks were automated.
• Seventy percent fewer audit findings appeared in the next review.
• Nine thousand hours a year moved from paperwork to delivery.
• Two point five million dollars in annual savings were projected from efficiency and penalties avoided.
The gains came from clear scopes, fast reviews, live cost telemetry, and signed logs. Not from a clever prompt.
Actionable leader checklist
• Inventory your tools and set scopes at the gateway.
• Stand up review lanes that protect edges without stopping flow.
• Publish cost per task and value per task.
• Log prompts, retrieval sources, tool calls, approvals, and rollbacks.
• Run a standing review that ends in scale, fix, or sunset.
• Require a one-minute evidence export for any route that touches sensitive systems.
❓ Frequently Asked Questions (FAQs)
Q1.What belongs in the agent registry?
A1. Register every tool with owner, inputs, outputs, side effects, risk class, default scopes, and approval path. Include version history and signatures. Enforce scope at the gateway so a prompt cannot bypass permissions.
Q2. How do we prevent review from slowing delivery?
A2. Use triage. Let low risk and high confidence pass. Send medium risk to a fast queue with a strict service level. Escalate only the edge cases. Track approval time, override rate, and false blocks and tune thresholds every week.
Q3. How do we show ROI to the board?
A3. Publish cost per task, value per task, and P95 latency by route. Include blocked actions, rollback time, and incident completeness. Compare to the pre-control baseline. If cost falls, latency tightens, and incidents have complete packets, ROI is clear.